
#include <Tokenizer.h>
Public Member Functions | |
| Tokenizer (const SBuf &inBuf) | |
| SBuf | buf () const |
| yet unparsed data More... | |
| SBuf::size_type | parsedSize () const |
| number of parsed bytes, including skipped ones More... | |
| bool | atEnd () const |
| whether the end of the buffer has been reached More... | |
| const SBuf & | remaining () const |
| the remaining unprocessed section of buffer More... | |
| void | reset (const SBuf &newBuf) |
| reinitialize processing for a new buffer More... | |
| bool | token (SBuf &returnedToken, const CharacterSet &delimiters) |
| bool | prefix (SBuf &returnedToken, const CharacterSet &tokenChars, SBuf::size_type limit=SBuf::npos) |
| bool | suffix (SBuf &returnedToken, const CharacterSet &tokenChars, SBuf::size_type limit=SBuf::npos) |
| bool | skipSuffix (const SBuf &tokenToSkip) |
| bool | skip (const SBuf &tokenToSkip) |
| bool | skip (const char tokenChar) |
| bool | skipOne (const CharacterSet &discardables) |
| SBuf::size_type | skipAll (const CharacterSet &discardables) |
| void | skipRequired (const char *description, const SBuf &tokenToSkip) |
| bool | skipOneTrailing (const CharacterSet &discardables) |
| SBuf::size_type | skipAllTrailing (const CharacterSet &discardables) |
| bool | int64 (int64_t &result, int base=0, bool allowSign=true, SBuf::size_type limit=SBuf::npos) |
| SBuf | prefix (const char *description, const CharacterSet &tokenChars, SBuf::size_type limit=SBuf::npos) |
| int64_t | udec64 (const char *description, SBuf::size_type limit=SBuf::npos) |
| int64() wrapper but limited to unsigned decimal integers (for now) More... | |
Protected Member Functions | |
| SBuf | consume (const SBuf::size_type n) |
| convenience method: consumes up to n bytes, counts, and returns them More... | |
| SBuf::size_type | success (const SBuf::size_type n) |
| convenience method: consume()s up to n bytes and returns their count More... | |
| SBuf | consumeTrailing (const SBuf::size_type n) |
| convenience method: consumes up to n last bytes and returns them More... | |
| SBuf::size_type | successTrailing (const SBuf::size_type n) |
| convenience method: consumes up to n last bytes and returns their count More... | |
| void | undoParse (const SBuf &newBuf, SBuf::size_type cParsed) |
| reset the buffer and parsed stats to a saved checkpoint More... | |
Private Attributes | |
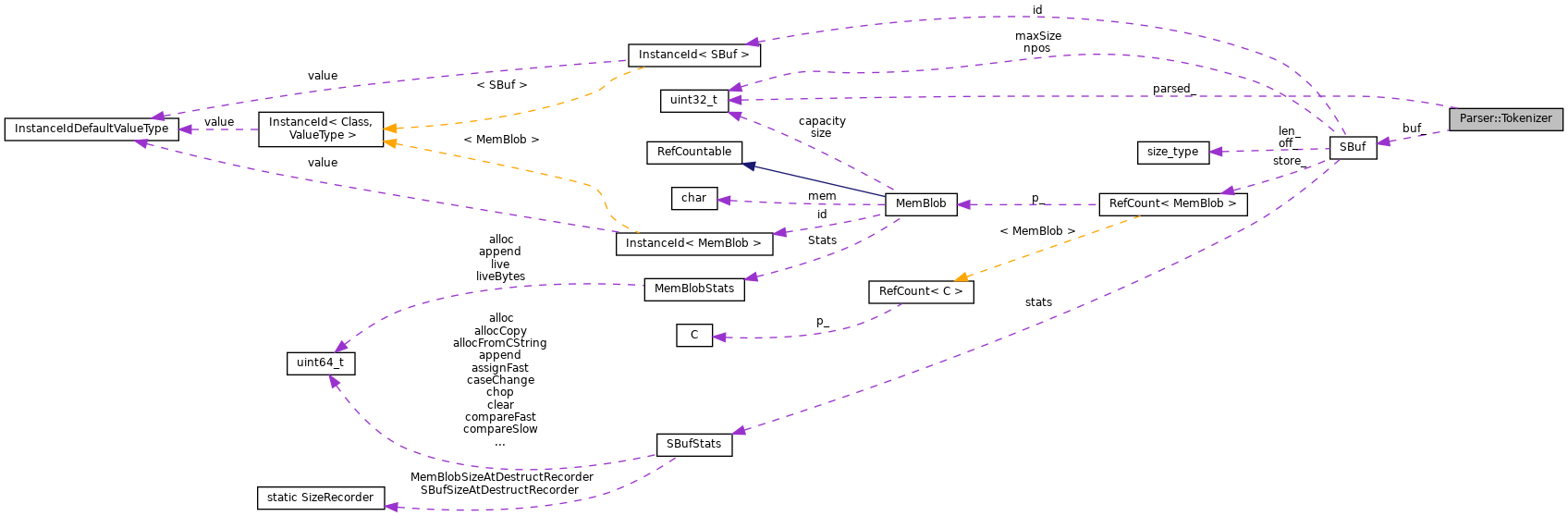
| SBuf | buf_ |
| yet unparsed input More... | |
| SBuf::size_type | parsed_ |
| bytes successfully parsed, including skipped More... | |
Detailed Description
Lexical processor to tokenize a buffer.
Allows arbitrary delimiters and token character sets to be provided by callers.
All methods start from the beginning of the input buffer. Methods returning true consume bytes from the buffer. Methods returning false have no side-effects.
Definition at line 29 of file Tokenizer.h.
Constructor & Destructor Documentation
◆ Tokenizer()
|
inlineexplicit |
Definition at line 32 of file Tokenizer.h.
Member Function Documentation
◆ atEnd()
|
inline |
Definition at line 41 of file Tokenizer.h.
References buf_, and SBuf::isEmpty().
Referenced by AnyP::Uri::Encode(), ProxyProtocol::IntegerToFieldType(), Ip::NfMarkConfig::Parse(), and Security::PeerOptions::parseOptions().
◆ buf()
|
inline |
Definition at line 35 of file Tokenizer.h.
References buf_.
Referenced by getNfmark(), and TestTokenizer::testTokenizerInt64().
◆ consume()
|
protected |
Definition at line 22 of file Tokenizer.cc.
References buf_, SBuf::consume(), debugs, SBuf::length(), and parsed_.
◆ consumeTrailing()
|
protected |
Definition at line 40 of file Tokenizer.cc.
References SBuf::consume(), debugs, and SBuf::npos.
◆ int64()
| bool Parser::Tokenizer::int64 | ( | int64_t & | result, |
| int | base = 0, |
||
| bool | allowSign = true, |
||
| SBuf::size_type | limit = SBuf::npos |
||
| ) |
Extracts an unsigned int64_t at the beginning of the buffer.
strtoll(3)-alike function: tries to parse unsigned 64-bit integer at the beginning of the parse buffer, in the base specified by the user or guesstimated; consumes the parsed characters.
- Parameters
-
result Output value. Not touched if parsing is unsuccessful. base Specify base to do the parsing in, with the same restrictions as strtoll. Defaults to 0 (meaning guess) allowSign Whether to accept a '+' or '-' sign prefix. limit Maximum count of characters to convert.
- Returns
- whether the parsing was successful
Definition at line 238 of file Tokenizer.cc.
References INT64_MAX, INT64_MIN, SBuf::length(), SBuf::rawContent(), xisalpha, xisdigit, and xisupper.
Referenced by getNfmark(), ProxyProtocol::IntegerToFieldType(), Security::PeerOptions::parseOptions(), and TestTokenizer::testTokenizerInt64().
◆ parsedSize()
|
inline |
Definition at line 38 of file Tokenizer.h.
References parsed_.
Referenced by ProxyProtocol::Parse().
◆ prefix() [1/2]
| SBuf Parser::Tokenizer::prefix | ( | const char * | description, |
| const CharacterSet & | tokenChars, | ||
| SBuf::size_type | limit = SBuf::npos |
||
| ) |
prefix() wrapper but throws InsufficientInput if input contains nothing but the prefix (i.e. if the prefix is not "terminated")
Definition at line 100 of file Tokenizer.cc.
◆ prefix() [2/2]
| bool Parser::Tokenizer::prefix | ( | SBuf & | returnedToken, |
| const CharacterSet & | tokenChars, | ||
| SBuf::size_type | limit = SBuf::npos |
||
| ) |
Extracts all sequential permitted characters up to an optional length limit.
Note that Tokenizer cannot tell whether the prefix will continue when/if more input data becomes available later.
- Return values
-
true one or more characters were found, the sequence (string) is placed in returnedToken false no characters from the permitted set were found
Definition at line 79 of file Tokenizer.cc.
References debugs, CharacterSet::name, and SBuf::npos.
Referenced by AnyP::Uri::Encode(), TestTokenizer::testTokenizerPrefix(), and TestTokenizer::testTokenizerSkip().
◆ remaining()
|
inline |
Definition at line 44 of file Tokenizer.h.
References buf_.
Referenced by AnyP::Uri::Encode(), Auth::SchemesConfig::expand(), ProxyProtocol::Parse(), TestTokenizer::testTokenizerPrefix(), TestTokenizer::testTokenizerSkip(), and TestTokenizer::testTokenizerSuffix().
◆ reset()
|
inline |
Definition at line 47 of file Tokenizer.h.
References undoParse().
◆ skip() [1/2]
| bool Parser::Tokenizer::skip | ( | const char | tokenChar | ) |
skips a given single character
- Returns
- whether the character was skipped
Definition at line 200 of file Tokenizer.cc.
References debugs.
◆ skip() [2/2]
| bool Parser::Tokenizer::skip | ( | const SBuf & | tokenToSkip | ) |
skips a given character sequence (string)
- Returns
- whether the exact character sequence was found and skipped
Definition at line 189 of file Tokenizer.cc.
References debugs, and SBuf::length().
Referenced by AnyP::Uri::Encode(), ProxyProtocol::IntegerToFieldType(), ProxyProtocol::Parse(), ProxyProtocol::One::Parse(), Ip::NfMarkConfig::Parse(), and TestTokenizer::testTokenizerSkip().
◆ skipAll()
| SBuf::size_type Parser::Tokenizer::skipAll | ( | const CharacterSet & | discardables | ) |
Skips all sequential characters from the set, in any order.
- Returns
- the number of skipped characters
Definition at line 137 of file Tokenizer.cc.
References debugs, and CharacterSet::name.
Referenced by TestTokenizer::testTokenizerSkip().
◆ skipAllTrailing()
| SBuf::size_type Parser::Tokenizer::skipAllTrailing | ( | const CharacterSet & | discardables | ) |
Removes all sequential trailing characters from the set, in any order.
- Returns
- the number of characters removed
Definition at line 222 of file Tokenizer.cc.
References debugs, CharacterSet::name, and SBuf::npos.
Referenced by Auth::SchemesConfig::expand().
◆ skipOne()
| bool Parser::Tokenizer::skipOne | ( | const CharacterSet & | discardables | ) |
Skips a single character from the set.
- Returns
- whether a character was skipped
Definition at line 161 of file Tokenizer.cc.
References debugs, and CharacterSet::name.
Referenced by ProxyProtocol::FieldNameToFieldType(), and TestTokenizer::testTokenizerSkip().
◆ skipOneTrailing()
| bool Parser::Tokenizer::skipOneTrailing | ( | const CharacterSet & | discardables | ) |
Removes a single trailing character from the set.
- Returns
- whether a character was removed
Definition at line 211 of file Tokenizer.cc.
References debugs, and CharacterSet::name.
Referenced by TestTokenizer::testTokenizerSuffix().
◆ skipRequired()
| void Parser::Tokenizer::skipRequired | ( | const char * | description, |
| const SBuf & | tokenToSkip | ||
| ) |
skips a given character sequence (string); does nothing if the sequence is empty
- Exceptions
-
exception on mismatching prefix or InsufficientInput
Definition at line 149 of file Tokenizer.cc.
References Here, SBuf::isEmpty(), SBuf::startsWith(), and ToSBuf().
◆ skipSuffix()
| bool Parser::Tokenizer::skipSuffix | ( | const SBuf & | tokenToSkip | ) |
skips a given suffix character sequence (string) Operates on the trailing end of the buffer.
Note that Tokenizer cannot tell whether the buffer will gain more data when/if more input becomes available later.
- Returns
- whether the exact character sequence was found and skipped
Definition at line 172 of file Tokenizer.cc.
References debugs, SBuf::length(), and SBuf::npos.
Referenced by TestTokenizer::testTokenizerSuffix().
◆ success()
|
protected |
Definition at line 33 of file Tokenizer.cc.
◆ successTrailing()
|
protected |
Definition at line 55 of file Tokenizer.cc.
◆ suffix()
| bool Parser::Tokenizer::suffix | ( | SBuf & | returnedToken, |
| const CharacterSet & | tokenChars, | ||
| SBuf::size_type | limit = SBuf::npos |
||
| ) |
Extracts all sequential permitted characters up to an optional length limit. Operates on the trailing end of the buffer.
Note that Tokenizer cannot tell whether the buffer will gain more data when/if more input becomes available later.
- Return values
-
true one or more characters were found, the sequence (string) is placed in returnedToken false no characters from the permitted set were found
Definition at line 117 of file Tokenizer.cc.
References SBuf::consume(), SBuf::rbegin(), and SBuf::rend().
Referenced by TestTokenizer::testTokenizerSuffix().
◆ token()
| bool Parser::Tokenizer::token | ( | SBuf & | returnedToken, |
| const CharacterSet & | delimiters | ||
| ) |
Basic strtok(3): Skips all leading delimiters (if any), extracts all characters up to the next delimiter (a token), and skips all trailing delimiters (at least one must be present).
Want to extract delimiters? Use prefix() instead.
Note that Tokenizer cannot tell whether the trailing delimiters will continue when/if more input data becomes available later.
- Returns
- true if found a non-empty token followed by a delimiter
Definition at line 61 of file Tokenizer.cc.
References DBG_DATA, debugs, CharacterSet::name, and SBuf::npos.
Referenced by Auth::SchemesConfig::expand(), and TestTokenizer::testTokenizerToken().
◆ udec64()
| int64_t Parser::Tokenizer::udec64 | ( | const char * | description, |
| SBuf::size_type | limit = SBuf::npos |
||
| ) |
Definition at line 316 of file Tokenizer.cc.
◆ undoParse()
|
inlineprotected |
Member Data Documentation
◆ buf_
|
private |
Definition at line 176 of file Tokenizer.h.
Referenced by atEnd(), buf(), consume(), remaining(), and undoParse().
◆ parsed_
|
private |
Definition at line 177 of file Tokenizer.h.
Referenced by consume(), parsedSize(), and undoParse().
The documentation for this class was generated from the following files:
- src/parser/Tokenizer.h
- src/parser/Tokenizer.cc